




Hello everybody! 👋
I was analyzing a dataframe 📝 with a column of prices. Unfortunately, it was formatted as text, not as numbers ($4000.00, for example). After searching for posible ways of solving this issue, I managed to do it using regular expressions 💪.
What are regular expressions? 🤔
Regular expression are search patterns, that are useful to find and replace characters. In my case, I used them to get rid of the $ sign. After converting the column values to float (I needed the decimal numbers), it's easy to continue working.
Let's see the code with a csv file I just made up:
# Disclaimer: it may be repetitive to see the code first and then
# the screenshot, but you can't copy code from the image :)
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
store = pd.read_csv("store.csv")
store
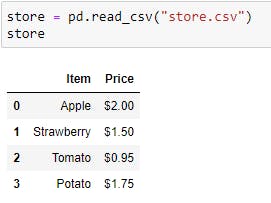
First, I've checked the data types:
store.dtypes
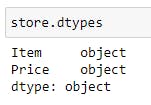
We can see that column "Price" is an Object, so I can't use that values to make any calculations or plots. This is the tricky part:
store["Price"] = store["Price"].str.replace('[\$]', '').astype(float)
store
# And now I'll check the dtypes:
store.dtypes
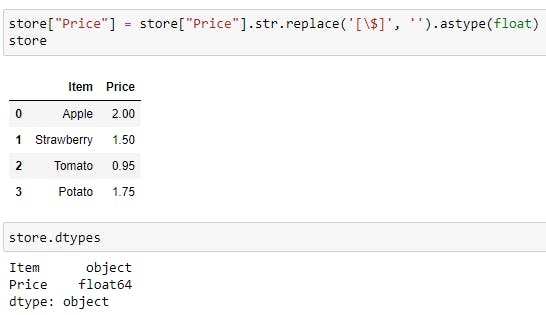
What's happening here? First, we have to select the column to modify (in this case, "Price"). Next step is deleting the character "$". We can use the .str method and the replace() function for this, along with regular expressions. In this case, we ask to "replace the character '$'" -> '[\$]' with "Nothing" -> ''.
As a result, we can now manipulate that column in order to do calculations 💻 or plots 📊, for example:
X = store["Item"]
Y = store["Price"]
fig, ax = plt.subplots()
ax.bar(X, Y);
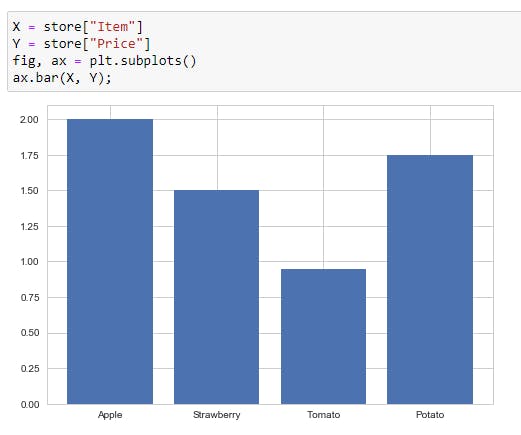
Ok, that's it for now. If you use a different workaround, let me know, I find this one pretty easy to follow. Before I go, here's a cool resource to test regular expressions.
Until next time! 🙋♂️
(The images from the cover were downloaded for free from Flaticon).